Review Sentiment Scoring: Building Your Own Framework for Accurate Analysis
Master review sentiment scoring with lexicon-based and machine learning approaches. Build scoring rules for your domain, handle edge cases, and benchmark accuracy against human raters.
# Review Sentiment Scoring: Building Your Own Framework for Accurate Analysis
Sentiment scoring converts qualitative feedback (text) into quantitative signals (numbers). A 5-star review is easy: stars = sentiment. But what about a customer's support ticket: "Love the product, hate the pricing"? Or a Discord message: "Finally shipped the feature we've been asking for, but it's buggy"?
Mixed sentiment is the norm in real feedback. That's where review sentiment scoring frameworks matter. The framework decides: does this message score as +0.8 (mostly positive) or +0.5 (balanced)? The difference determines whether you flag this customer for churn risk or celebrate them as happy.
This guide covers sentiment scoring frameworks, how to build one for your domain, and how to validate accuracy.
Why sentiment scoring matters differently than star ratings
Star ratings (1-5 stars) are explicit. Sentiment scoring extracts implied emotion from text. They answer different questions:
1. Star ratings answer "would you recommend this?"
A 5-star review says "yes, I'd recommend it." A 1-star says "no." Clear signal, but limited context. You don't know if they're rating the product, support, pricing, or onboarding.
2. Sentiment scoring answers "what is the emotional tone?"
"The product is great but the price increase killed our budget." That's mixed sentiment. Scoring models can assign +0.6 (positive overall, with concerns) and tag the negative aspects (pricing objection). Now you know which theme to address.
3. Sentiment scoring finds hidden signals in ambiguous feedback
A review says: "Finally fixed the bug we reported 3 months ago, but we're already using [competitor]." Star rating? Probably 3-4 (mixed). Sentiment score? +0.4 (mostly negative — they're switching). The sentiment model catches the churn signal that a star rating would miss.
4. Sentiment scoring scales to unstructured feedback
You can't ask customers to rate their Discord message. Sentiment scoring extracts polarity from raw text across every source: reviews, tickets, chat, social media.
The sentiment scoring landscape
Approach 1: Lexicon-based scoring (rule-based)
Maintain a dictionary of words/phrases and their sentiment weights:
| Word/phrase | Sentiment weight | Context |
|---|---|---|
| "love," "amazing," "incredible" | +0.9 | Positive superlatives |
| "great," "good," "helpful" | +0.6 | Positive modifiers |
| "okay," "decent," "acceptable" | +0.2 | Neutral-positive |
| "hate," "terrible," "broken" | -0.9 | Negative superlatives |
| "slow," "confusing," "buggy" | -0.6 | Negative modifiers |
| "overpriced," "expensive," "waste" | -0.8 | Domain-specific negative |
Scoring algorithm: 1. Tokenize text (split into words) 2. Look up each word in sentiment lexicon 3. Apply intensity modifiers ("very good" = +0.6 × 1.5 = +0.9) 4. Apply negation handling ("NOT good" = -0.6) 5. Sum all weighted words 6. Normalize to -1.0 to +1.0 scale
Example: - Text: "I love the product but the UI is confusing and support is slow" - "love" = +0.9 - "product" = 0 (neutral) - "confusing" = -0.6 - "slow" = -0.6 - Sum: +0.9 - 0.6 - 0.6 = -0.3 (slightly negative overall) - Final score: -0.3 (flagged as "mixed with concerns")
Strength: Fast, interpretable, domain-customizable. You control the rules. Weakness: Misses context. "This is not good" and "This is good" both contain "good," requiring explicit negation handling.
Approach 2: Machine learning sentiment classification
Train a model on labeled data (human-scored reviews) to predict sentiment automatically:
- Collect training data: 500-1000 reviews + human sentiment labels (-1, 0, +1)
- Extract features: word frequencies, n-grams, topic distributions
- Train classifier: SVM, Naive Bayes, or neural network
- Validate: test on held-out reviews, measure accuracy
- Deploy: use trained model to score new reviews
Example accuracy: - Random baseline: 33% (just guessing positive/neutral/negative) - Rule-based lexicon: 65-75% - ML classifier (domain-trained): 85-92% - State-of-the-art (transformers like GPT): 95%+
Strength: Learns domain patterns (e.g., "pricey" = negative in your SaaS, but neutral in luxury goods). Handles context better. Weakness: Requires training data, slower inference, less interpretable.
Approach 3: Aspect-based sentiment (ABSA)
Standard scoring assigns one sentiment to a whole review. Aspect-based scoring assigns sentiment to specific features:
- Review: "Love the dashboard, hate the API documentation"
- Standard score: +0.5 (mixed)
- Aspect-based score:
See What Your Reviews Really Say
Paste any product URL and get an AI-powered SWOT analysis in under 60 seconds.
Try It Free →Why this matters: Now you know exactly which features drive positive/negative sentiment. You can prioritize: "API documentation is consistently -0.7 across 30+ reviews → assign PM to improve docs."
Building your review sentiment scoring framework
Step 1: Define your scoring scale and labels
3-class scale (simple): - Positive: +0.5 to +1.0 - Neutral: -0.5 to +0.5 - Negative: -1.0 to -0.5
5-class scale (granular): - Very positive: +0.8 to +1.0 - Positive: +0.4 to +0.8 - Neutral: -0.2 to +0.4 - Negative: -0.8 to -0.2 - Very negative: -1.0 to -0.8
Recommendation: Start with 5-class. It captures nuance without over-complicating.
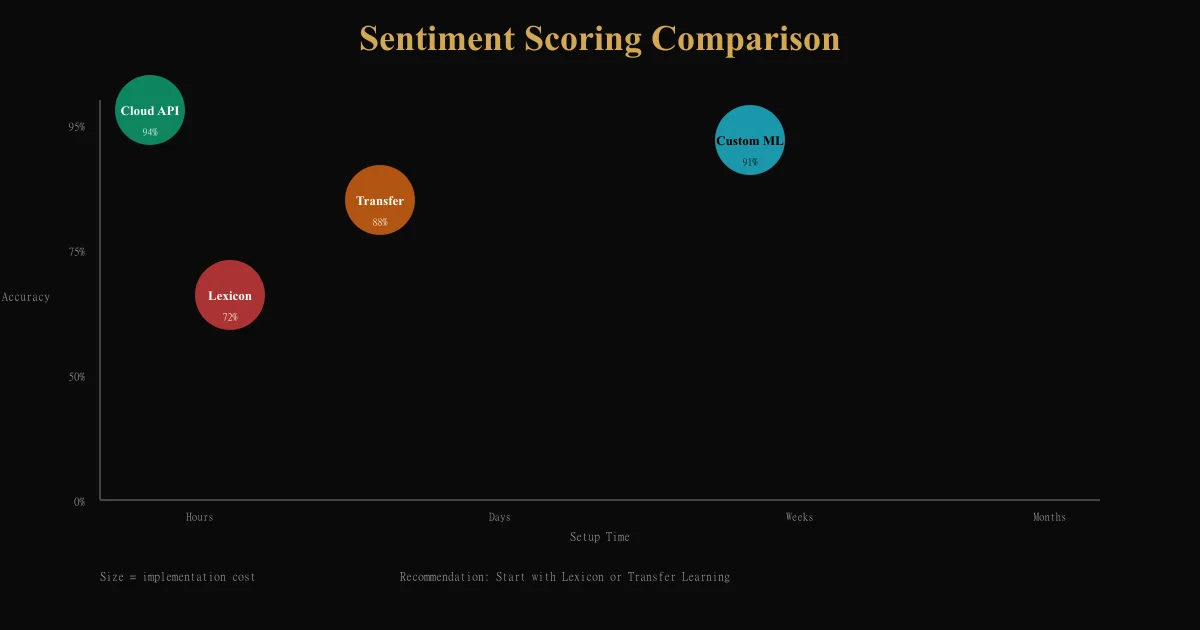
Step 2: Choose your scoring approach
| Approach | Setup time | Accuracy | Customization | Cost |
|---|---|---|---|---|
| Lexicon-based | 4-8 hours | 65-75% | Full (you control rules) | Free |
| Transfer learning (pre-trained) | 30 mins | 85-90% | Medium (fine-tune) | Free-$100/mo |
| Custom ML classifier | 2-4 weeks | 85-95% | High (retrain) | $500-2000 + time |
| Commercial API (Google, AWS, Azure) | 30 mins | 90%+ | None (black box) | $0.01-0.10 per request |
For most SaaS: Start with lexicon-based (2-week implementation), validate accuracy, then invest in ML if needed.
Step 3: Build your domain-specific lexicon
Start with a general sentiment lexicon (500-1000 words), then add domain-specific terms:
General: - positive: love, amazing, great, excellent, helpful, quick, reliable, responsive, intuitive - negative: hate, terrible, broken, slow, confusing, buggy, unresponsive, unclear
Domain-specific (SaaS review analysis): - Positive: "easy integration," "great documentation," "responsive support," "quick onboarding," "powerful API" - Negative: "overpriced," "lacking features," "poor documentation," "slow support," "steep learning curve"
Domain-specific (e-commerce review analysis): - Positive: "fast shipping," "great packaging," "true to size," "high quality" - Negative: "arrived damaged," "poor quality," "not as described," "slow delivery"
For each term, assign: - Sentiment polarity (+1 to -1) - Intensity (mild, moderate, strong) - Context (is it always negative, or context-dependent?)
Step 4: Handle edge cases and negations
| Case | Example | Handling |
|---|---|---|
| Negation | "NOT a good product" | Flip sign: "good" → "NOT good" = negative |
| Intensifiers | "VERY good," "so good" | Multiply weight: good × 1.5 = stronger positive |
| Comparison | "Better than [competitor]" | Both comparative adjectives + competitor mention = positive |
| Sarcasm | "Oh great, another bug" | Requires context knowledge; fallback to keyword "bug" = negative |
| Conditional | "Would be great if [feature added]" | Feature request = neutral-to-positive; not a complaint |
| Aspect mention | "Love X, hate Y" | Split into aspects; separately score X and Y |
Step 5: Validate accuracy against human raters
Sample 100-200 reviews and score them: 1. Manual scoring: 2-3 humans independently score each review 2. Model scoring: Your sentiment model scores the same reviews 3. Compare: Calculate agreement between human and model 4. Measure accuracy: % of reviews where model score matches consensus human score
Target accuracy: 85%+ (within ±0.2 score on -1 to +1 scale).
If accuracy is 70-80%: Add more domain-specific rules or collect training data for ML classifier. If accuracy is < 70%: Your approach (lexicon vs. ML) might not fit your data. Try different method.
Case study: SaaS review sentiment scoring
A project management tool implemented sentiment scoring across 2,000 G2 reviews:
Baseline (lexicon-based): - Average score: +0.52 (mostly positive) - Distribution: 65% positive, 20% neutral, 15% negative - Manual validation: 78% accuracy
Findings: - Pricing theme: -0.6 average (negative) - Ease of use theme: +0.75 average (very positive) - Feature completeness: +0.45 average (mixed; missing specific integrations)
Action: - Doubled down on "ease of use" marketing (competitive advantage) - Built business case for pricing model change based on 150+ negative pricing comments - Prioritized Zapier + Slack integrations (top feature gaps by count)
Result: - New customer sentiment on pricing posts: improved from -0.6 to -0.2 (less negative) - Feature gap sentiment: +0.55 to +0.7 (after shipping integrations) - G2 rating improvement: 4.5 → 4.7 stars over 6 months
Ready to try AI-powered review analysis?
Get 2 free SWOT reports per month. No credit card required.
Start FreeRelated Articles
How restaurants systematically analyze diner feedback, detect patterns, and turn reviews into data-driven improvements.
Aspect-Based Sentiment Analysis Explained: Beyond Star RatingsLearn what aspect-based sentiment analysis (ABSA) is, how it works under the hood, and why it delivers deeper insights than document-level sentiment or star ratings. Includes real examples, an NLP pipeline breakdown, business applications across industries, and practical guidance on getting started.
Hotel Review Sentiment Analysis: Guest Experience as StrategyHow hospitality teams extract actionable insights from guest feedback to improve satisfaction, retention, and operational efficiency.