Review Scraping: Legal Guide & Best Practices for Data Collection
Navigate the legal landscape of review scraping with this comprehensive guide. Covers the hiQ vs LinkedIn precedent, CFAA implications, platform-specific rules for Amazon, Google, Yelp, and Trustpilot, plus ethical best practices and legal alternatives for collecting review data.

Every business that works with review data eventually faces the same question: can I legally scrape reviews from the internet? The answer — maddeningly, but honestly — is "it depends." It depends on which platform, which jurisdiction, what data you collect, how you store it, and what you do with it afterward.
The legal landscape around web scraping has shifted dramatically since 2017, and review data sits in a particularly interesting gray area. Reviews are publicly visible, written by third parties, hosted on platforms that claim various rights over them, and protected (or not) by an evolving patchwork of laws, court decisions, and platform terms of service.
This guide breaks down what we actually know — from landmark court cases to platform-specific rules to practical best practices — so you can make informed decisions about how to collect and use review data.

The Legal Framework: What the Law Actually Says
Before diving into platform-specific rules, you need to understand the legal foundations that govern web scraping in the United States and Europe. Three primary legal frameworks apply.
The Computer Fraud and Abuse Act (CFAA)
The CFAA was enacted in 1986, originally designed to prosecute computer hackers. It criminalizes accessing a computer "without authorization" or "exceeding authorized access." For years, companies used the CFAA to argue that scraping their websites constituted unauthorized access — essentially treating a terms of service violation as a federal crime.
The critical problem with applying the CFAA to web scraping is that publicly accessible websites are, by definition, accessible to the public. If you can reach a page by typing a URL into your browser, arguing that automated access to that same page constitutes "unauthorized access" requires some creative legal reasoning.
"The CFAA was written to prevent hacking into protected systems, not to regulate how people access publicly available web pages. Using it to criminalize scraping is like using trespassing law to prosecute someone for looking at your house from the sidewalk."
The hiQ Labs v. LinkedIn Decision
The most significant legal precedent for web scraping came from the hiQ Labs v. LinkedIn case, which wound through federal courts from 2017 to 2022. hiQ scraped publicly available LinkedIn profile data to build workforce analytics products. LinkedIn sent a cease-and-desist letter and began blocking hiQ's scrapers. hiQ sued for an injunction.
The Ninth Circuit Court of Appeals ruled in hiQ's favor on several key points:
- Public data is public. Scraping publicly accessible data does not violate the CFAA because there is no "authorization" barrier to bypass.
- Cease-and-desist letters do not create CFAA liability. A company cannot transform public data into private data simply by sending a letter telling you not to access it.
- Anti-competitive concerns matter. LinkedIn's attempt to block hiQ from accessing public data raised competition issues, as LinkedIn was effectively trying to monopolize publicly available information.
However, the Supreme Court vacated and remanded the case in 2021, and the Ninth Circuit reaffirmed its position in 2022. The legal principle stands, but it has not been universally adopted by all circuits.
What hiQ Means for Review Scraping
The hiQ decision directly applies to review scraping in several ways:
| Principle | Application to Reviews |
|---|---|
| Public data can be scraped | Reviews visible without login are generally fair game |
| CFAA does not apply to public pages | Scraping public review pages is not "hacking" |
| Terms of service violations are not CFAA violations | Breaking a platform's TOS is a contract issue, not a criminal one |
| Technical barriers matter | Bypassing CAPTCHAs or login walls changes the analysis |
GDPR and European Privacy Law
In Europe, the General Data Protection Regulation (GDPR) adds a significant layer of complexity. Reviews often contain personal data — reviewer names, locations, sometimes photos and personal details mentioned in the review text.
Under GDPR, collecting personal data requires a legal basis. The most commonly cited basis for scraping is "legitimate interest," but this requires a balancing test between your business interest and the data subject's privacy rights. Key considerations include:
- Minimization principle. You should collect only the data you actually need. If you need sentiment analysis, you may not need reviewer names.
- Storage limitations. You cannot store personal data indefinitely. Have a retention policy and enforce it.
- Right to erasure. If a reviewer requests deletion of their data from your systems, you need a mechanism to comply.
- Transparency. Data subjects have a right to know their data is being processed. This is practically difficult with scraped data but legally required.
The California Consumer Privacy Act (CCPA)
The CCPA grants California residents the right to know what personal information businesses collect about them, request deletion, and opt out of its sale. If your scraped review data includes information from California residents — which, given California's population, it almost certainly does — you need compliance mechanisms in place.
Platform-Specific Rules: What Each Major Site Allows
The legal framework provides general principles, but each review platform has its own terms of service, technical defenses, and enforcement posture. Here is the current state of play.
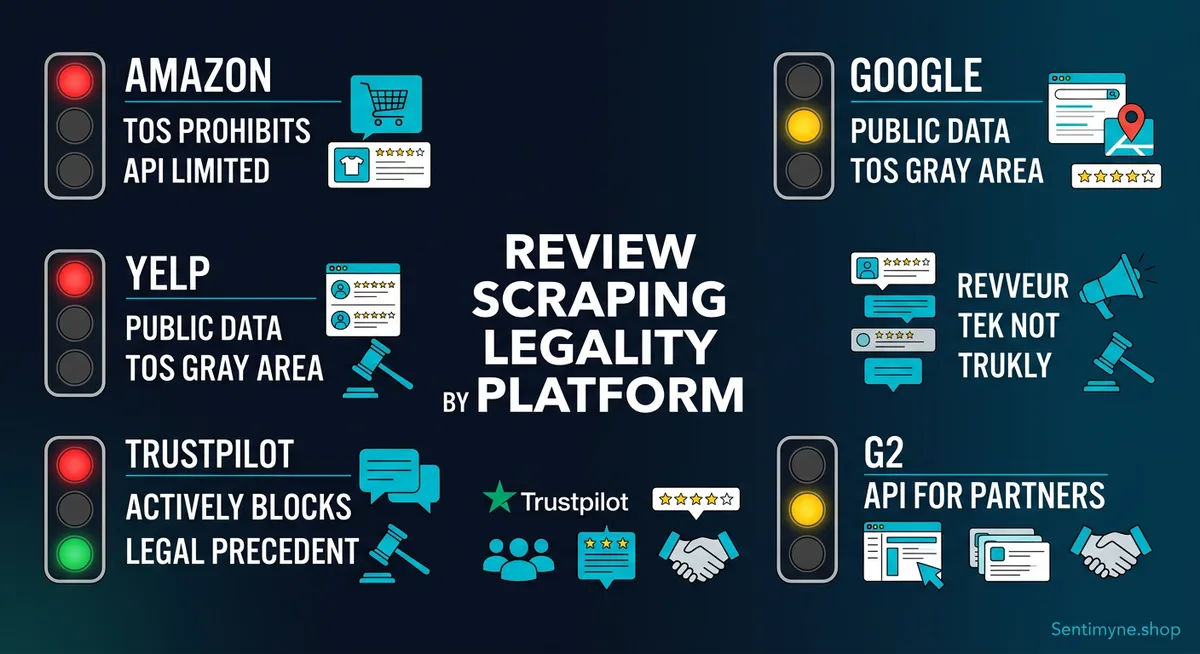
Amazon
Official position: Scraping is explicitly prohibited in Amazon's Conditions of Use. Section 4 states that you may not use "any robot, spider, scraper, or other automated means to access the Services for any purpose."
Enforcement posture: Aggressive. Amazon actively detects and blocks scrapers using sophisticated bot detection (device fingerprinting, behavioral analysis, CAPTCHA challenges). Amazon has also pursued legal action against scraping operations.
API alternative: Amazon's Product Advertising API provides some review data, but it is limited and requires an Amazon Associates account. Amazon removed detailed review access from the API in 2019, making programmatic access to review content extremely difficult through official channels.
Practical reality: Amazon reviews are among the most scraped data on the internet despite the prohibition. Third-party services that aggregate Amazon review data operate in a legal gray area. The data is publicly visible, but Amazon's terms explicitly forbid automated collection.
Google (Google Maps / Google Business Profile)
Official position: Google's Terms of Service prohibit scraping. Specifically, Google prohibits "automated queries" against Google services without express permission.
Enforcement posture: Moderate. Google uses CAPTCHAs, rate limiting, and IP blocking to deter scrapers. However, Google has not been as litigious about scraping as some other platforms.
API alternative: The Google Places API provides review data, including text, ratings, and author information. However, it is limited to 5 reviews per place in the basic response. Google's API pricing makes large-scale review extraction expensive.
Practical reality: Google review scraping is extremely common. Many review aggregation and reputation management tools rely on scraped Google data. The sheer volume of Google reviews — billions across millions of businesses — makes this a constant cat-and-mouse game.
Yelp
Official position: Yelp is one of the most aggressive defenders of its review data. Its terms prohibit scraping, and Yelp has filed multiple lawsuits against companies that scraped its reviews.
Enforcement posture: Very aggressive. Yelp employs sophisticated bot detection, actively monitors for scraping activity, and has pursued legal action. In 2020, Yelp sued a company for scraping reviews, arguing breach of contract and violations of the CFAA and California's Comprehensive Computer Data Access and Fraud Act.
API alternative: Yelp's Fusion API provides limited review data — up to 3 review excerpts per business. This is intentionally restricted to prevent API-based review extraction.
Legal history: Yelp's legal position is that reviews are proprietary content. While reviewers write the text, Yelp claims rights to the compiled database of reviews. This argument has had mixed success in court, but Yelp's willingness to litigate makes it a high-risk target for scraping.
Trustpilot
Official position: Trustpilot's terms prohibit scraping, but Trustpilot has a more open approach to data access than most platforms.
Enforcement posture: Moderate. Trustpilot focuses more on providing legitimate access channels than on blocking scrapers.
API alternative: Trustpilot offers a Business API that provides access to review data for businesses that have claimed their Trustpilot profile. The API includes review text, ratings, dates, and reviewer information. For businesses reviewing their own reviews, this is the cleanest legal path.
Practical reality: Trustpilot's relatively open API makes scraping less necessary. For competitive analysis (accessing competitors' reviews), the API does not help — you need to be the business owner. This creates a gap that scrapers fill.
G2
Official position: G2 prohibits automated access in its terms of service.
Enforcement posture: Moderate. G2 uses standard anti-bot measures.
API alternative: G2 offers API access for partners and customers through its G2 for Sellers program. This is primarily designed for B2B software companies that want to integrate their own review data. Access to competitor reviews via API is limited.
Practical reality: G2 reviews are among the most valuable in the B2B software space because of their structured format (pros, cons, ratings across multiple dimensions). This makes them a high-value scraping target despite the prohibition.
App Stores (Apple App Store, Google Play)
Official position: Both Apple and Google prohibit scraping their app stores.
API alternative: Apple provides the App Store Connect API, and Google provides the Google Play Developer API. Both give developers access to their own app's reviews but not competitors' reviews.
Practical reality: App store review scraping is widespread. Multiple commercial services offer app review data, and open-source scraping tools exist for both platforms.
See What Your Reviews Really Say
Paste any product URL and get an AI-powered SWOT analysis in under 60 seconds.
Try It Free →Best Practices for Legal Review Data Collection
Regardless of which approach you take, following these best practices reduces your legal exposure and keeps your data collection ethical.
1. Use Official APIs Whenever Available
APIs represent the platform's authorized channel for data access. When an API provides the data you need, use it. Yes, APIs are often more limited and more expensive than scraping. That is the point — the platform is controlling access in a way it considers acceptable.
APIs available for review data:
- Google Places API (limited reviews, paid)
- Trustpilot Business API (own reviews, free for claimed businesses)
- Yelp Fusion API (3 review excerpts per business)
- App Store Connect API (own app reviews)
- Google Play Developer API (own app reviews)
- G2 API (partner access)
2. Respect robots.txt
The robots.txt file communicates a website's preferences about automated access. While robots.txt is not legally binding in most jurisdictions, respecting it demonstrates good faith and reduces the likelihood of legal challenges.
Check robots.txt before scraping any site. If a platform explicitly disallows scraping review pages in robots.txt, proceeding with scraping weakens your legal position if challenged.
3. Do Not Bypass Technical Access Controls
There is a meaningful legal distinction between scraping publicly accessible pages and bypassing access controls to reach restricted content. If a website requires login, uses CAPTCHAs, or employs other technical barriers, circumventing these measures significantly increases your legal risk.
The CFAA's "exceeding authorized access" provision is more clearly applicable when you bypass technical controls. The hiQ case dealt with public data — once you start bypassing barriers, the legal calculus changes.
4. Minimize Personal Data Collection
If you are analyzing review sentiment and themes, you may not need reviewer names, profile photos, or other personal identifiers. Collect only the data fields you actually need for your analysis:
| Data Field | Need for Analysis? | Privacy Risk |
|---|---|---|
| Review text | Essential | Low (if anonymized) |
| Star rating | Essential | None |
| Date posted | Important | None |
| Reviewer name | Rarely needed | Medium |
| Reviewer photo | Not needed | High |
| Reviewer location | Sometimes useful | Medium |
| Reviewer profile URL | Not needed | Medium |
5. Implement Rate Limiting
Even if you have a legal right to access public data, hammering a server with thousands of requests per second can constitute a denial-of-service attack. Rate limit your requests to avoid degrading the platform's performance.
A reasonable approach: limit requests to no more than one per second for any given domain. Add random delays between requests to avoid detection patterns. Respect HTTP 429 (Too Many Requests) responses.
6. Store Data Responsibly
Your data storage practices matter both legally and ethically:
- Encrypt stored review data — especially if it contains personal information.
- Set retention limits — do not store review data indefinitely. Analyze it, extract insights, and delete the raw data.
- Document your legal basis — if operating under GDPR, document your legitimate interest assessment.
- Have a deletion mechanism — be prepared to delete specific records if requested.
7. Do Not Republish Raw Reviews
Scraping reviews for analysis is one thing. Republishing the full text of scraped reviews on your own website is a much stronger copyright concern. Review platforms and individual reviewers may have copyright claims to the text.
Use review data for analysis and insights. Do not build a competing review directory using scraped content.
Alternatives to DIY Scraping
For most businesses, building and maintaining a scraping infrastructure is a poor use of resources. The legal complexity, technical challenges (anti-bot measures, page structure changes, CAPTCHA solving), and ongoing maintenance make DIY scraping expensive even before legal risks enter the equation.
Official API Aggregation
Several services aggregate review data from multiple platform APIs into a single interface. These services handle the API integrations, authentication, and data normalization. They are limited to what the APIs provide, which means incomplete review data from some platforms, but they operate within clearly legal boundaries.
Review Management Platforms
Services like Birdeye, Podium, and ReviewTrackers aggregate reviews from multiple platforms using a combination of APIs and authorized partnerships. These are designed for businesses monitoring their own reviews, not competitive analysis.
AI-Powered Review Analysis Tools
The smartest alternative to scraping is using a tool that handles the data collection problem entirely. Rather than scraping reviews yourself, analyzing them in spreadsheets, and trying to extract insights manually, purpose-built analysis tools handle the entire pipeline.
Sentimyne takes this approach to its logical conclusion. Instead of requiring you to scrape, export, or manually collect reviews, Sentimyne pulls review data from 12+ platforms and delivers a complete SWOT analysis in 60 seconds. The platform handles the data collection through authorized methods, runs AI-powered sentiment and theme analysis, and produces actionable intelligence — no scraping infrastructure needed.
This matters because the entire point of collecting review data is to extract insights. If you can get directly to the insights without building, maintaining, and legally defending a scraping operation, you eliminate the highest-risk, lowest-value part of the process.
"The goal was never to scrape reviews. The goal was to understand what customers are saying. Tools that skip straight to understanding save you from solving a problem that does not need to be your problem."
Manual Collection
For small-scale analysis — say, a one-time competitive analysis of a few dozen reviews — manual collection is perfectly legal and surprisingly effective. Reading through reviews and noting themes by hand works for volumes under a few hundred. This is not scalable, but it is unambiguously legal and often reveals nuances that automated analysis misses.
Ethical Considerations Beyond Legality
Legal compliance is the floor, not the ceiling. Several ethical considerations should guide your approach to review data:
Reviewer Expectations
When someone writes a review on Yelp, they expect it to be read by other consumers and the business owner. They may not expect their review to be scraped, aggregated into a dataset, analyzed by machine learning models, and used to train AI systems. Consider whether your use of review data aligns with reasonable reviewer expectations.
Competitive Fairness
Using review analysis for competitive intelligence is standard business practice. Using scraped data to manipulate review platforms — generating fake reviews, gaming algorithms, or attacking competitors — is both unethical and illegal.
Data Accuracy and Context
Reviews are written in specific contexts. A negative restaurant review during a pandemic lockdown may reflect circumstances that no longer exist. A positive review from 2019 may describe a product version that has been entirely replaced. When analyzing scraped review data, consider temporal context and avoid drawing conclusions from data that may no longer be representative.
Transparency with Stakeholders
If you produce reports or analyses based on review data, be transparent about your data sources and collection methods. Stakeholders deserve to know whether your insights come from authorized API data, manual collection, or scraping.
When Scraping Is Defensible vs. When It Is Not
Based on the current legal landscape and ethical best practices, here is a framework for evaluating whether a specific scraping activity is defensible:
Generally Defensible
- Scraping publicly visible review data for internal analysis
- Collecting aggregate statistics (average ratings, review counts) from public pages
- One-time research projects with small data volumes
- Academic research on review patterns
- Scraping your own reviews from platforms where you cannot access them via API
Gray Area
- Regular, ongoing scraping of public review data at scale
- Building commercial products entirely on scraped review data
- Scraping review data that includes reviewer personal information
- Collecting reviews from platforms that have sent cease-and-desist notices
Generally Not Defensible
- Bypassing login walls, CAPTCHAs, or other technical access controls
- Scraping at volumes that degrade platform performance
- Republishing full review text on competing platforms
- Scraping private or gated review content
- Ignoring robots.txt exclusions specific to review pages
Frequently Asked Questions
Is it legal to scrape Google reviews?
Google's Terms of Service prohibit scraping, but the hiQ v. LinkedIn precedent suggests that scraping publicly visible data does not violate the CFAA. However, Google can still pursue breach of contract claims based on its TOS. The practical risk is low for small-scale collection, but increases significantly for commercial-scale operations. Using the Google Places API is the safest approach, though it limits you to 5 reviews per business.
Can Amazon sue me for scraping product reviews?
Amazon can pursue legal action based on breach of its Conditions of Use (a contract claim) and potentially under state computer fraud statutes. While the CFAA argument is weakened by the hiQ precedent for public data, Amazon has deep legal resources and a history of enforcement. The safer approach is using Amazon's Product Advertising API or a tool like Sentimyne that aggregates review insights through authorized channels.
Do I need consent to analyze someone's online review?
For the text content of publicly posted reviews, explicit consent is generally not required in the United States. However, under GDPR, processing personal data from reviews (reviewer names, locations, etc.) requires a legal basis — typically "legitimate interest" with a documented balancing test. The safest approach is to anonymize review data before analysis, stripping personal identifiers and retaining only the text and ratings.
What is the difference between scraping reviews and using a review analysis tool?
Scraping involves directly extracting data from websites using automated tools, which puts the legal and technical burden on you. Review analysis tools like Sentimyne handle data collection through authorized methods (APIs, partnerships, authorized access) and deliver processed insights. The key difference is liability: when you scrape, you bear all legal risk; when you use a specialized tool, the data collection compliance is handled by the service provider.
What happens if a platform sends me a cease-and-desist for scraping?
A cease-and-desist letter is a warning, not a court order — you are not legally required to comply. However, ignoring it creates a paper trail showing you were aware the platform objected to your activity, which strengthens any future legal claim they pursue. The pragmatic response is to stop scraping that specific platform, evaluate whether an API alternative exists, and consider whether a tool that handles data collection through authorized channels might be a better long-term solution.
Ready to try AI-powered review analysis?
Get 2 free SWOT reports per month. No credit card required.
Start FreeRelated Articles
Navigate the legal landscape of review data analysis including GDPR, CCPA, platform terms of service, and review scraping legality. Covers privacy-first best practices for businesses using review intelligence tools.
Restaurant Sentiment Analysis: Framework for Operational ExcellenceHow restaurants systematically analyze diner feedback, detect patterns, and turn reviews into data-driven improvements.
Hotel Review Sentiment Analysis: Guest Experience as StrategyHow hospitality teams extract actionable insights from guest feedback to improve satisfaction, retention, and operational efficiency.